預防醫學/前瞻性定群研究方法
| 醫學電子書 >> 《預防醫學》 >> 定群研究 >> 前瞻性定群研究方法 |
| 預防醫學 |
|
|
|
目錄 |
一、暴露組選擇
暴露組應已處在某種暴露因素中或已有某種特殊暴露史,並能提供可靠的暴露因素的歷史,且便於追蹤與觀察。
(一)特殊暴露的人群
選擇由於職業關係或其他原因暴露於某危險因素特別嚴重的人作為定群研究對象,不但所需要的人數較少,而且較易發現暴露與患病之間是否存在聯繫。如研究放射線與白血病的關係時,選用接受放射線治療的患者;研究聯苯胺與膀胱癌的關係時,選用染料工人;研究肺癌的危險因素時,選用石棉工人。
(二)一個地區的全部人口或其樣本
有時可在一地區人群中進行定群研究。選擇條件首先是便於研究。例如,在美國麻薩諸塞州的Framingham鎮已進行多年的心臟病定群研究,在1948年開始時以當時30~59歲人口的2/3的一個隨機樣本作為研究對象。因為當地人口流動性小,居民配合,有一所高水平的醫院等,便於隨訪,能得到完整的資料。
一個可疑病歷必須有較高的人群暴露率,並且所研究的病又有較高的發病率或死亡率才適合於用全人群作定群研究。
(三)便於隨訪的人群
為了便於隨訪,往往選擇一個團體,或以醫療就診和隨訪觀察結果方面特別方便的人群作為研究對象,可以節省人力、物力,並可提高隨訪質量和結果判斷的可靠程度。例如Doll和Hill選擇了所有登記註冊的開業醫生。選擇屬於團體的人群,樣本代表全人群的可能性稍差,但是能降低失訪率,同時提高調查結果的可靠性。
二、對照組的選擇
對照組的設立是為了與暴露組比較。對照組與暴露組應具有可比性,即對照組人群除暴露因素的影響外,其他各種因素的影響或人群的特徵,如年齡、性別、職業、民族等,都應儘可能與暴露組相似。同時在資料收集完畢,進行分析時,還應作一次均衡檢驗,以考核兩組資料的可比性。
對照組常用以下幾種形式:
(一)內對照
若調查對象是一個整體人群,人群內部暴露於某因素的便為暴露組,而非暴露或以暴露級別最低的一組便為對照組;不需另外設對照組或非暴露組。例如,調查人群中血脂水平,可以水平最低的組列為對照。
(二)人群對照
不另設對照,而是以人群為對照。在職業流行病學研究中,常以某職業人群為暴露組,與該地區整個人群的發病(或死亡)率進行比較分析。以人群為對照,應注意對照組與暴露組人群在地理與時間的一致性。
特殊暴露人群人數一般不多,不能得到可靠的分年齡、性別和原因的專率供直接比較,一般須採用標化死亡比或標化發病比作間接比較,兩者均須計算標準誤並作顯著性檢驗。
(三)另設對照組
選擇一個與暴露組在年齡、性別、民族、居住地區等方面相似的非暴露組作為對照組進行隨訪,作為與暴露組比較的基準。例如研究放射線對放射科醫師死亡率的影響時,可以在同地區醫院內眼科醫師作對照組。
(四)多種對照
為了增強判斷依據,可將上述方法綜合起來,設立多種對照,進行多重比較。如內對照、人群對照、非暴露組對照等。這樣可以增加判斷的依據。
三、樣本大小的估計
定群研究樣本大小的估計應根據:
1.暴露組的事件發生率(P1)的估計值;
2.非暴露組的事件發生率(P0)的估計值;
3.第一類錯誤機率α;
4.第二類錯誤機率β。
在該4個數值確定後,可用下式估計暴露組與非暴露組需觀察的人數。
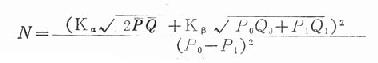
公式中N為每一組所需調查人數。
Q1=1-P1,Q0=1-P0
P=(P0+P1)/2,Q=1-P
Kα與Kβ分別為α及β值的常態分佈分位數,該數可從常態分佈的分位數表中查出。
非暴露組的發病率P0可以根據人群一般發病水平來代替。而暴露組的發病率P1難以估計,若能夠估計相對危險度(RR),則P1=RR×P0,RR可從預調查或文獻資料中估計,也可用OR來代替,P1=OR×P0,OR可從病例對照研究中得來。
例 擬用定群研究方法研究孕婦暴露於某種藥物與嬰兒先天性心臟病之間的聯繫。假定已知非暴露組的發病機率P0=0.08,估計RR=2,當α=0.05,β=0.10時,估計需要的樣本含量。
Kα=1.960,Kβ=1.282
P0=0.008,RR=2,P1=2×0.008=0.016
P=(0.008+0.016) /2=0.012
Q=0.988,Q1=0.984,Q2=0.992
代入公式:
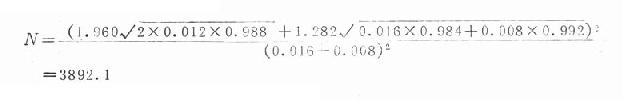
即每組需要樣本含量為3892人。
四、資料的來源與收集
確定暴露組與非暴露組後,需收集對疾病的發生或死亡頻率可能有影響的一般資料,如年齡、性別、婚姻、文化程度、經濟收入、家庭人口、人口遷移等。
(一)從查閱現有的記錄收集
特殊暴露人群的職業史或醫療記錄常有暴露水平或個體暴露劑量的的資料,這是暴露史的唯一可靠來源。查閱現有記錄不僅可了解研究對象本人暴露的性質和劑量,同時其主要優點是具有較高的客觀性。
(二)調查詢問收集
有時被研究對象的有些研究因素無現成記錄,例如煙、酒、飲食等生活習慣、體力活動等,必須向被研究對象本人了解。通常採用調查表方式由調查員詢問時填寫或通信調查。
(三)通過醫學檢查或檢驗收集
有些研究因素屬於被研究對象對生理特徵或生化指標,必須通過檢查或檢驗才能獲得數據,例如血壓、身高、體重、血脂、血糖等。
(四)從環境資料收集
環境資料包括家庭環境、居住環境、工作環境、區域環境等。根據不同的研究假設,可作不同暴露的測定。
(五)追蹤結局收集
追蹤確定各成員的結局,採用隨訪的方法進行。隨訪的方法有直接方法,即通過函件調查、訪問調查、定期調查等。間接方法就是利用醫院病歷、死亡登記、疾病報告、勞保資料等,根據結局的性質選用。判斷結局的標準必須在隨訪開始時規定,應保持穩定,以便前後比較。隨訪時間的長短,根據不同疾病的潛隱期、疾病的自然史及已暴露時間來確定。
五、定群研究資料分析
定群研究資料分析主要是計算各組發病率、發病密度或死亡率,其次對組間率的差異進行統計學檢查,差異有統計學意義則進一步確定因素與疾病聯繫的強度。定群研究資料歸納見表30-2。
表30-2 定群研究資料歸納表
| 組別 | 病例 | 非病例 | 合計 | 發病率 |
| 暴露組 | a | b | a+b=N1 | a/N1 |
| 非暴露組 | c | d | c+d=N0 | c/N0 |
| a+c=m1 | b+d=m0 |
定群研究所比較的是發病率或死亡率即a/N1,與c/N0,如a/N1>c/N0,則某因素與發病有聯繫,甚至是因果聯繫。
(一)率的計算
1.累積發病率(cumulative incidence)觀察期間人群比較固定,且能穩定地維持在一個較長的觀察期,可用累積發病率(或死亡率)。計算公式為:

2.發病密度(ivcidence density)若暴露人口不固定,人群產生了較大的變動,例如由於工作調動、死於其他疾病、中途加入等,應將變動著的人群轉變為人時數代替人數業計算,此種發病率稱發病密度。人時就是將人與時間因素結合起來作為率分母的單位,常用的單位是人年,是一個觀察對象被觀察滿一年計為一人年。分子為觀察期間發病或死亡人數。
(二)暴露人年計算
定群研究觀察時間較長,其間人口有動態變化,應採取一定方法計算「暴露人年數」,才能計算髮病率;否則,兩組成員由於進入開始觀察的時間不同,或因死亡、遷出及其他原因或早或晚地退出該組,而造成觀察時間的不同,即各組成員的暴露時間不同,可使發病率出現誤差。
1.大樣本中暴露人年的計算計算原則為:從觀察對象中剔除死亡、遷移及失去聯繫的人數,補充新加入的人數來折算人年。
可以年末12月31日的人數為終點及起點計算。上年12月31日觀察人數減去次年內所有死亡、遷移、失去聯繫及新加入人數的總和,得到次年末12月31日的觀察人數。兩個人數之和除以2,即得到該年內暴露人年數。表30-3為例說明不同年齡9年的合計暴露人年數。
表30-3 男性各年齡各年末存活人數
| 年齡組 | 1972. 12.31 |
1973. 12.31 |
1974. 12.31 |
1975 12.31 |
1976. 12.31 |
1977. 12.31 |
1978. 12.31 |
1979. 12.31 |
1980. 12.31 |
1981. 12.31 |
合計暴露 人年數 |
| <45 | 607 | 547 | 471 | 392 | 324 | 246 | 210 | 179 | 148 | 110 | 2875.5 |
| 45~54 | 598 | 596 | 604 | 599 | 603 | 625 | 598 | 562 | 538 | 510 | 5279 |
| 55~64 | 369 | 406 | 433 | 472 | 493 | 496 | 519 | 524 | 513 | 526 | 4303.5 |
| 65及以上 | 62 | 75 | 95 | 111 | 132 | 158 | 180 | 210 | 251 | 286 | 1386 |
| 合計 | 1636 | 1624 | 1603 | 1574 | 1552 | 1525 | 1507 | 475 | 1450 | 1432 | 13844 |
(李婉先等,1984)
以小於45歲組為例計算合計暴露人年數:
(607+547)÷2+(547+471)÷2+(471+392)÷2(392+324)÷2+(324+246)÷2+(246+210)÷2+(210+179)÷2+(179+148)÷2+(148+110)÷2= 2875.5
如此9年內共有3名45歲以下男性死亡,男性45歲以下組的死亡率為:3÷2875.5×10萬=104.3/10萬人年。
2.小樣本可以直接計算若樣本不大,且各人隨訪年數不同,可先算出各人隨訪人年數,再計算總人年數;而且因為隨訪期內各人的年齡在增長,到一定的日期年齡超過原屬年齡組上限時,會進入下一年齡組。所以還可以算出各年齡組的總人年數以及不同的年份的總人年數,結合同年齡或同年份發生的病例數,則可算出各年齡組或年份的發病率。
例有3人從開始觀察日起至1981年1月1日止,逐個計算人年的方法。上例並得出不同年齡組的暴露人年,見表30-4、表30-5。
表30-4 3例出生日期與進出研究時間
| 對象編號 | 出生日期 | 進入研究時間 | 退出研究時間 |
| 1 | 1927.03.21 | 1966.07.19 | 1977.09.14(遷居外地) |
| 2 | 1935.04.09 | 1961.11.11 | 1973.12.01(死亡) |
| 3 | 1942.11.12 | 1970.02.01 | 1981.01.01(觀察結束時健在) |
資料來源:錢宇平;流行病學第二版1986
表30-5 3例人年的計算
| 對象1 1927年3月21日出生 |
對象2 1935年4月9日出生 |
對象3 1942年11月12日出生 |
暴露 人年 |
|
| 25~ | 61.11.11~65.04.08 共3年4個月天即3.41人年 |
70.02.01~72.11.11 共2年9個月天即2.78人年 |
6.19 | |
| 30~ | 65.04.09~70.04.08 共5.00人年 |
72.11.12~77.11.11 共5.00人年 |
10.00 | |
| 35~ | 66.07.19~67.03.20 共8個月即0.67人年 |
70.04.09~73.12.01 共3年7個月天即3.65人年 |
77.11.12~81.01.01 共3年1個月天即3.14人年 |
7.46 |
| 40~ | 67.03.21~72.03.20 共5.00人年 |
5.00 | ||
| 45~ | 72.03.21~77.03.20 共5.00人年 |
5.00 | ||
| 50~54 | 77.03.21~77.09.14 共5個月天即0.48人年 |
0.48 | ||
| 累計 | 66.07.19~77.09.14 共11.15人年 |
61.11.11~73.12.1 共12.06人年 |
70.0201~81.01.01 共10.92人年 |
34.13 人年 |
資料來源:錢宇平:流行病學第二版1986
(三)統計學檢驗
暴露組與非暴露組間率的差異要進行統計學檢驗。當發病率高時,可用u檢驗。如果發病率比較低,則改用二項分布或泊松分布檢驗。檢驗方法查閱有關統計學書籍。
(四)聯繫強度的測量
為了估計疾病死亡與暴露的聯繫強度,常用的測量指標有相對危險度、特異危險度、人群特異危險度。
1.相對危險度(relative risk)又稱「危險比」(risk ratio)或「率比」(rate ratio)。是暴露組發病率(或死亡率)與非暴露組發病率(或死亡率)的比值,簡稱RR。
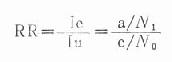
式中Ie=暴露組發病率,Iu=非暴露組發病率。
它說明暴露組發病或死亡為非暴露組的倍數。
RR>1,說明暴露因素與疾病有「正」的聯繫。暴露越多,發病越多,可能是致病因素。
RR=1,說明暴露因素與疾病無聯繫。
RR<1,說明暴露因素與疾病有「負」的聯繫。暴露越多,疾病越少,具有保護意義。
表30-6中提供的判斷數據可供參考。
表30-6 相對危險度與聯繫強度
| 相對危險度 | 聯繫的強度 | |
| 0.9~1.0 | 1.0~1.1 | 無 |
| 0.7~0.8 | 1.2~1.4 | 弱 |
| 0.4~0.6 | 1.5~2.9 | 中等 |
| 0.1~0.3 | 3.0~9.0 | 強 |
| <0.1 | 10~ | 很強 |
2.特異危險度(attributable risk)又稱歸因危險度或率差(rate difference),簡稱AR。特異危險度為暴露組發病(或死亡)率與非暴露組發病(或死亡)率之差。
AR=Ie-Iu=a/N1-c/N0
特異危險度表示完全由暴露因素所致之危險度。
3.人群特異危險度(population attributable risk)簡稱PAR。
PAR=It-Iu
It=全人群某病發病率或死亡率
Iu=非暴露者某病發病率或死亡率
人群特異危險度是測量在人群中因暴露於某因素所致的發病率或死亡率。
| 關於「預防醫學/前瞻性定群研究方法」的留言: | |
|
目前暫無留言 | |
| 添加留言 | |